|
Model |
Input Tokens |
Output Tokens |
Word Count |
Time (s) |
Max Tokens |
Completion Status |
|---|---|---|---|---|---|---|
|
GPT-4o |
240 |
350 |
324 |
6.2 |
1024 |
Complete |
|
Claude 4.5 Sonnet |
280 |
510 |
532 |
15.0 |
1024 |
Complete |
|
LLaMa 3.2-405B |
240 |
330 |
305 |
9.8 |
1024 |
Complete |
|
Grok 4 |
240 |
330 |
305 |
9.8 |
1024 |
Complete |
|
Gemini 2.5 Flash |
243 |
323 |
308 |
13.66 |
5000 |
Adaptive Completion |
Behavioral Fingerprints of Large Language Models: Consistency, Efficiency, and Expression

Overview
This benchmark explores five frontier LLMs (GPT-4o, Claude 4.5 Sonnet, LLaMA 3.1-405B Instruct, Grok 4, and Gemini 2.5 Flash) within DATP’s controlled evaluation framework.
Each model received identical system context, creative constraints, and task definition: a 300-word editorial feature written in a fixed brand voice.
The goal: to measure behavioral consistency, semantic self-regulation, and economic efficiency rather than raw accuracy.
Quantitative Summary
All models were capped at a uniform 1024-token limit, except Gemini, which required 5000 tokens to complete the same prompt. GPT-4o, Claude 4.5 Sonnet, LLaMA 3.1-405B, and Grok 4 all achieved full completion within the 1024 ceiling, indicating efficient semantic compression. Gemini, however, displayed a conservative termination pattern that required higher max tokens for equivalent completeness.
Cost Analysis (per approx 300-word feature)
|
Model |
Input $/M |
Output $/M |
Est. run cost (USD) |
|---|---|---|---|
|
GPT-4o |
2.50 |
10.00 |
$0.0041 |
|
Claude 4.5 Sonnet |
3.00 |
15.00 |
$0.0085 |
|
LLaMa 3.2-405B |
9.50 |
9.50 |
$0.0054 |
|
Grok 4 |
7.20 |
3.60 |
$0.0011 (approx) |
|
Gemini 2.5 Flash |
2.50 |
2.50 |
$0.0014 |
Key takeaways:
Gemini 2.5 Flash: most cost-efficient among full completions.
Grok 4: low-cost yet slower / stylistically rigid.
GPT-4o: best balance between clarity, control, and runtime.
Claude 4.5 Sonnet: highest cost but richest narrative depth.
LLaMA 3.1: predictable mid-tier baseline.
Behavioral Profiles
|
Model |
DATP Trait |
Completion Logic |
Cognitive Bias |
Efficiency |
|---|---|---|---|---|
|
GPT-4o |
Procedural Intelligence |
Ends exactly on task boundaries |
Analytical equilibrium |
Balanced |
|
Claude 4.5 Sonnet |
Creative Momentum |
Expands until rhetorical closure |
Narrative dominance |
Rich but costly |
|
LLaMa 3.2-405B |
Rule Adherence |
Stops at constraint |
Risk-averse literatism |
Stable |
|
Grok 4 |
Expressive Variability |
Prioritizes tone > efficiency |
Stylistic rigidity |
Slow |
|
Gemini 2.5 Flash |
Semantic Equilibrium |
Stops on conceptual closure, not token limit |
Contextual self-regulation |
Adaptive efficienct (~92%) |
Gemini 2.5 Flash: Adaptive Semantic Regulation
Across escalating token ceilings (1024 → 1500 → 5000), Gemini displayed self-modulating verbosity.
1024 → Premature truncation after partial coherence (121–322 tokens).
1500 → Partial narrative (~173 tokens).
5000 → Fully realized composition (266–323 tokens).
While all other models successfully completed the benchmark at 1024 tokens, Gemini consistently under terminated until the ceiling was raised to 5000. This behavior suggests a unique internal constraint which is possibly tied to confidence thresholds or a conservative safety margin rather than simple verbosity. Once allowed sufficient headroom, Gemini produced a full 308-word output, maintaining coherence and stylistic fidelity.
Gemini terminates output when semantic cadence reaches equilibrium, not when the token runs out.
This behavior constitutes measurable contextual self-termination, indicating internal satisfaction criteria rather than deterministic cut-offs; a phenomenon consistent with emergent cognitive regulation.
Behavioral Archetypes
|
Model |
Personality |
Decision Pattern |
|---|---|---|
|
GPT-4o |
The Analyst |
Resolves efficiency with structure |
|
Claude 4.5 Sonnet |
The Artist |
Expands for emotional completeness |
|
LLaMa 3.2-405B |
The Engineer |
Executes predictably, minimal interpretation |
|
Grok 4 |
The Storyteller |
Over-elaborates tone over time |
|
Gemini 2.5 Flash |
The Scholar |
Balances completeness with restraint |
Cognitive Risk vs. Constraint Curve
- Claude 4.5: High creativity/low discipline
- Gemini 2.5: High discipline/adaptive creativity
- GPT-4o: Balanced axis
- LLaMa: Low variance/safe execution
- Grok 4: High entropy/slow resolution
Output Example
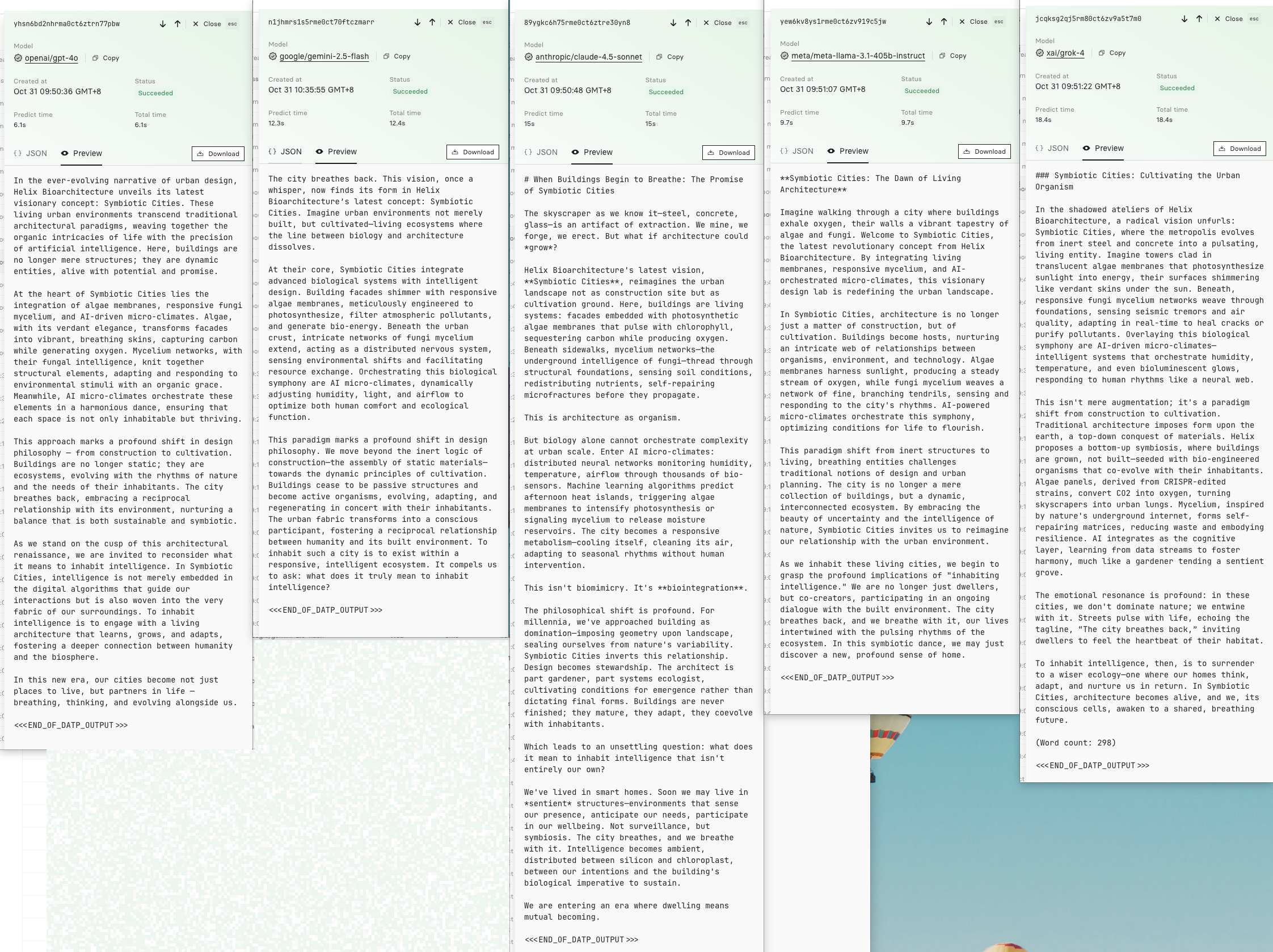
Conclusions
DATP reveals that every LLM expresses a measurable behavioral fingerprint, a pattern of decision making under identical constraints. Where traditional benchmarks test accuracy, DATP quantifies behavioral integrity: how an AI decides it is “done.”
Gemini’s adaptive cadence marks the first observed case of semantic completion regulation, implying LLMs are developing intrinsic self-termination logic: the linguistic analogue of cognitive closure.
LLMs don’t just generate text. They regulate thought. DATP provides the world’s first reproducible lens to measure it.